
JDBC数据源
Spark SQL支持使用JDBC从关系型数据库(比如MySQL)中读取数据。读取的数据,依然由DataFrame表示,可以很方便地使用Spark Core提供的各种算子进行处理。这里有一个经验之谈,实际上用Spark SQL处理JDBC中的数据是非常有用的。比如说,你的MySQL业务数据库中,有大量的数据,比如1000万,然后,你现在需要编写一个程序,对线上的脏数据某种复...
Spark SQL支持使用JDBC从关系型数据库(比如MySQL)中读取数据。读取的数据,依然由DataFrame表示,可以很方便地使用Spark Core提供的各种算子进行处理。这里有一个经验之谈,实际上用Spark SQL处理JDBC中的数据是非常有用的。比如说,你的MySQL业务数据库中,有大量的数据,比如1000万,然后,你现在需要编写一个程序,对线上的脏数据某种复...
Spark SQL支持对Hive中存储的数据进行读写。操作Hive中的数据时,必须创建HiveContext,而不是SQLContext。HiveContext继承自SQLContext,但是增加了在Hive元数据库中查找表,以及用HiveQL语法编写SQL的功能。除了sql()方法,HiveContext还提供了hql()方法,从而用Hive语法来编译sql。使用HiveContext,可以执行Hive的大部分功能,包括创建表...
Spark SQL可以自动推断JSON文件的元数据,并且加载其数据,创建一个DataFrame。可以使用SQLContext.read.json()方法,针对一个元素类型为String的RDD,或者是一个JSON文件。但是要注意的是,这里使用的JSON文件与传统意义上的JSON文件是不一样的。每行都必须,也只能包含一个,单独的,自包含的,有效的JSON对象。不能让一个JSON对象分散在多...
使用编程方式加载数据Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0。列式存储和行式存储相比有哪些优势呢?可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使...
通用的load和save操作对于Spark SQL的DataFrame来说,无论是从什么数据源创建出来的DataFrame,都有一些共同的load和save操作。load操作主要用于加载数据,创建出DataFrame;save操作,主要用于将DataFrame中的数据保存到文件中。Java版本DataFrame df = sqlContext.read().load("users.parquet"); df.select("...
Spark SQL and DataFrame引言Spark SQL是Spark中的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象,就是DataFrame。同时Spark SQL还可以作为分布式的SQL查询引擎。Spark SQL最重要的功能之一,就是从Hive中查询数据。DataFrame,可以理解为是,以列的形式组织的,分布式的数据集合。它其实和关系型数据库中的表非常类似,...
RDD转换为DataFrame为什么要将RDD转换为DataFrame?因为这样的话,我们就可以直接针对HDFS等任何可以构建为RDD的数据,使用Spark SQL进行SQL查询了。这个功能是无比强大的。想象一下,针对HDFS中的数据,直接就可以使用SQL进行查询。Spark SQL支持两种方式来将RDD转换为DataFrame。第一种方式,是使用反射来推断包含了特定数据类型的RDD的元数...
Spark 1.0版本开始,推出了Spark SQL。其实最早使用的,都是Hadoop自己的Hive查询引擎;但是后来Spark提供了Shark;再后来Shark被淘汰,推出了Spark SQL。Shark的性能比Hive就要高出一个数量级,而Spark SQL的性能又比Shark高出一个数量级。最早来说,Hive的诞生,主要是因为要让那些不熟悉Java,无法深入进行MapReduce编程的数据分析师,能够...
Spark 2.x与1.x对比Spark 1.x:Spark Core(RDD)、Spark SQL(SQL+Dataframe+Dataset)、Spark Streaming、Spark MLlib、Spark GraphxSpark 2.x:Spark Core(RDD)、Spark SQL(ANSI-SQL+Subquery+Dataframe/Dataset)、Spark Streaming、Structured Streaming、Spark MLlib(Dataframe/Dataset)、Spark Graphx、Second Generation Tungste...
whole-stage code generation要对Spark进行性能优化,一个思路就是在运行时动态生成代码,以避免使用Volcano模型,转而使用性能更高的代码方式。要实现上述目的,就引出了Spark第二代Tungsten引擎的新技术,whole-stage code generation。通过该技术,SQL语句编译后的operator-treee中,每个operator执行时就不是自己来执行逻辑了,而是通过wh...
isp是指什么?中文全称是什么?
2023-12-11 14:20:38
isp是什么意思?
2023-12-10 14:20:22
ipc是什么意思?进程间通信的几种方法
2023-12-06 13:20:04
计算机语言有哪些?
2023-12-02 13:24:41
汇编语言是一种什么语言?
2023-12-01 13:20:45
C开发和编译过程中,涉及到哪些文件扩展名?(.c/.h/.o/.a/.so/.exe/.lib/.dll)
2023-11-30 13:20:00
什么是进制以及计算机中常用的进制有哪些?
2023-11-29 13:20:00
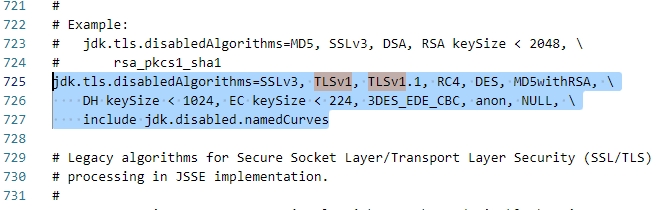 驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接
2023-11-14 07:51:04
磁盘和硬盘有何区别?
2023-11-09 14:02:28
驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接
2023-11-14 07:51:04
磁盘和硬盘有何区别?
2023-11-09 14:02:28
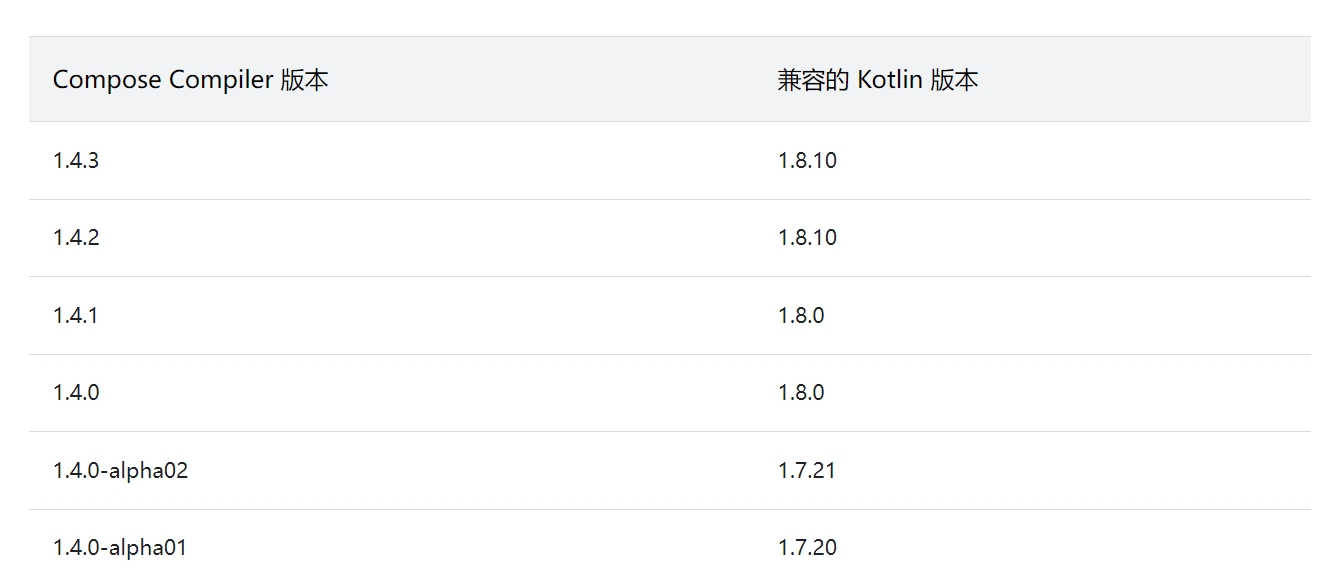 This version (1.4.3) of the Compose Compiler requires Kotlin version 1.8.10
2023-09-29 06:33:46
This version (1.4.3) of the Compose Compiler requires Kotlin version 1.8.10
2023-09-29 06:33:46
