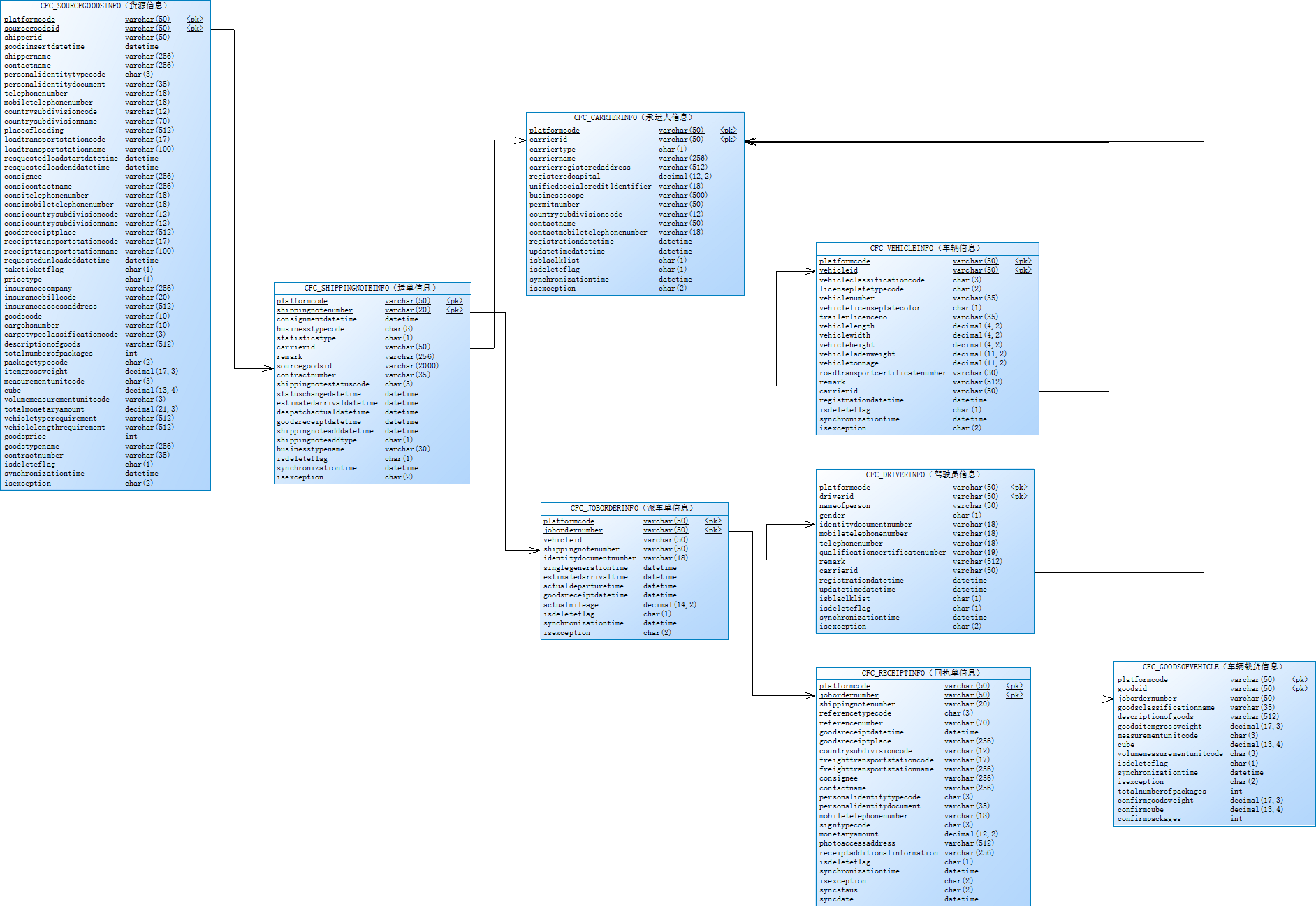
省无车承运人监测与服务平台接入前期准备工作
1、阅读《江苏省无车承运人监测与服务平台接入说明(省平台)》 和关系图.png2、准备前置机。(做好前置机安全防护工作开启防火墙,安装杀毒软件,定时备份数据等)前置机要求(1 台或 2 台):数据交换服务器 8 核 CPU, 32G 内存, 100GB 存储,Windows 2008 64 位操作系统以上。 (需提供远程权限)数据库服务器 8 核 CPU, 32G 内存, 500GB 存储(...


1、阅读《江苏省无车承运人监测与服务平台接入说明(省平台)》 和关系图.png2、准备前置机。(做好前置机安全防护工作开启防火墙,安装杀毒软件,定时备份数据等)前置机要求(1 台或 2 台):数据交换服务器 8 核 CPU, 32G 内存, 100GB 存储,Windows 2008 64 位操作系统以上。 (需提供远程权限)数据库服务器 8 核 CPU, 32G 内存, 500GB 存储(...

通用的load和save操作对于Spark SQL的DataFrame来说,无论是从什么数据源创建出来的DataFrame,都有一些共同的load和save操作。load操作主要用于加载数据,创建出DataFrame;save操作,主要用于将DataFrame中的数据保存到文件中。Java版本DataFrame df = sqlContext.read().load("users.parquet"); df.select("...
Spark SQL and DataFrame引言Spark SQL是Spark中的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象,就是DataFrame。同时Spark SQL还可以作为分布式的SQL查询引擎。Spark SQL最重要的功能之一,就是从Hive中查询数据。DataFrame,可以理解为是,以列的形式组织的,分布式的数据集合。它其实和关系型数据库中的表非常类似,...
RDD转换为DataFrame为什么要将RDD转换为DataFrame?因为这样的话,我们就可以直接针对HDFS等任何可以构建为RDD的数据,使用Spark SQL进行SQL查询了。这个功能是无比强大的。想象一下,针对HDFS中的数据,直接就可以使用SQL进行查询。Spark SQL支持两种方式来将RDD转换为DataFrame。第一种方式,是使用反射来推断包含了特定数据类型的RDD的元数...
Spark 1.0版本开始,推出了Spark SQL。其实最早使用的,都是Hadoop自己的Hive查询引擎;但是后来Spark提供了Shark;再后来Shark被淘汰,推出了Spark SQL。Shark的性能比Hive就要高出一个数量级,而Spark SQL的性能又比Shark高出一个数量级。最早来说,Hive的诞生,主要是因为要让那些不熟悉Java,无法深入进行MapReduce编程的数据分析师,能够...
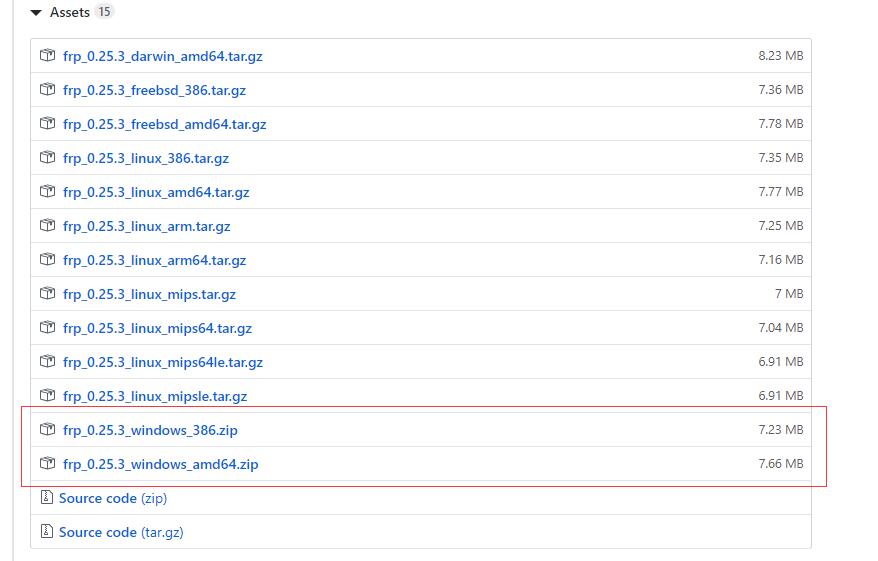
首先我们需要下载内网穿透工具frp的,下载地址是:https://github.com/fatedier/frp/releases目前最新的是0.25.3,frp_0.25.3_windows_amd64.zip用于64位的服务器,frp_0.25.3_windows_386.zip用于32位的服务器,当然如果你的服务器配置很低,可能还是会用到32位版本的。下载完后,我们解压,把文件中的frps.exe和frps.ini拷贝至服务器C盘的f...
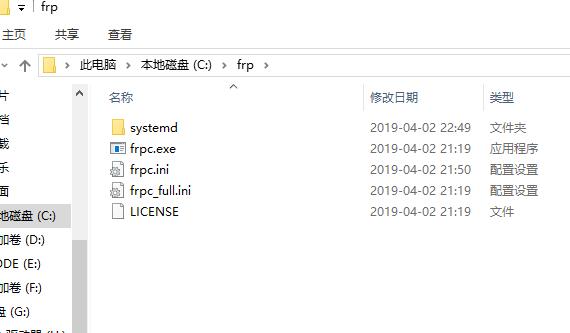
之前我们讲了frp在windows服务器下的配置,本课程我们讲下客户端frpc的配置,c就是client了。我们之前已经完成了frp的下载,不会下载的看我们之前的文章:Windows服务器端内网穿透工具frps安装及使用教程首先,我们把frpc.exe和frpc.ini拷贝至c盘,目录结构如下图所示,当然你拷贝至其他盘也是一样的,看个人喜好了。修改frpc.ini文件,[commo...
TeamViewer现在是越来越严格,本来是想买他的服务的,但是感觉太贵了,每年要1000多。而且最近我的TeamViewer打开一直提示:未就绪,请检查你的连接,我估计是ip是被封了。于是找到了frp,1000多我可以买个阿里云服务器了,平常做做远程连接,还能部署部署自己的网站博客等。frp 是一个可用于内网穿透的高性能的反向代理应用,支持 tcp, udp, ...
Spark 2.x与1.x对比Spark 1.x:Spark Core(RDD)、Spark SQL(SQL+Dataframe+Dataset)、Spark Streaming、Spark MLlib、Spark GraphxSpark 2.x:Spark Core(RDD)、Spark SQL(ANSI-SQL+Subquery+Dataframe/Dataset)、Spark Streaming、Structured Streaming、Spark MLlib(Dataframe/Dataset)、Spark Graphx、Second Generation Tungste...
whole-stage code generation要对Spark进行性能优化,一个思路就是在运行时动态生成代码,以避免使用Volcano模型,转而使用性能更高的代码方式。要实现上述目的,就引出了Spark第二代Tungsten引擎的新技术,whole-stage code generation。通过该技术,SQL语句编译后的operator-treee中,每个operator执行时就不是自己来执行逻辑了,而是通过wh...
省无车承运人监测与服务平台接入前期准备工作
2019-04-04 22:00:50
通用的load和save操作
2019-04-04 22:00:24
DataFrame使用
2019-04-04 18:00:37
使用反射方式将RDD转换为DataFrame
2019-04-04 12:00:25
SparkSQL简介
2019-04-03 22:00:25
Windows服务器端内网穿透工具frps安装及使用教程
2019-04-03 18:00:33
Windows客户端内网穿透工具frpc安装及使用教程
2019-04-03 12:55:21
前言
2019-04-03 12:00:45
Spark 2.x与1.x对比
2019-04-03 12:00:41
whole-stage code generation技术和vectorization技术
2019-04-03 12:00:18
