易用性:标准化SQL支持以及更合理的API
标准化SQL支持以及更合理的APISpark最引以为豪的几个特点就是简单、直观、表达性好。Spark 2.0为了继续加强这几个特点,做了两件事情:1、提供标准化的SQL支持;2、统一了Dataframe和Dataset两套API。在标准化SQL支...
标准化SQL支持以及更合理的APISpark最引以为豪的几个特点就是简单、直观、表达性好。Spark 2.0为了继续加强这几个特点,做了两件事情:1、提供标准化的SQL支持;2、统一了Dataframe和Dataset两套API。在标准化SQL支...
仅仅在spark1上搭建下载安装HIVE下载hive,下载bin版本,不要下载src版本将下载的hive包解压缩到/usr/local文件夹下修改夹名字为hive配置环境变量下载安装mysql安装mysql serveryum install -y mysql...
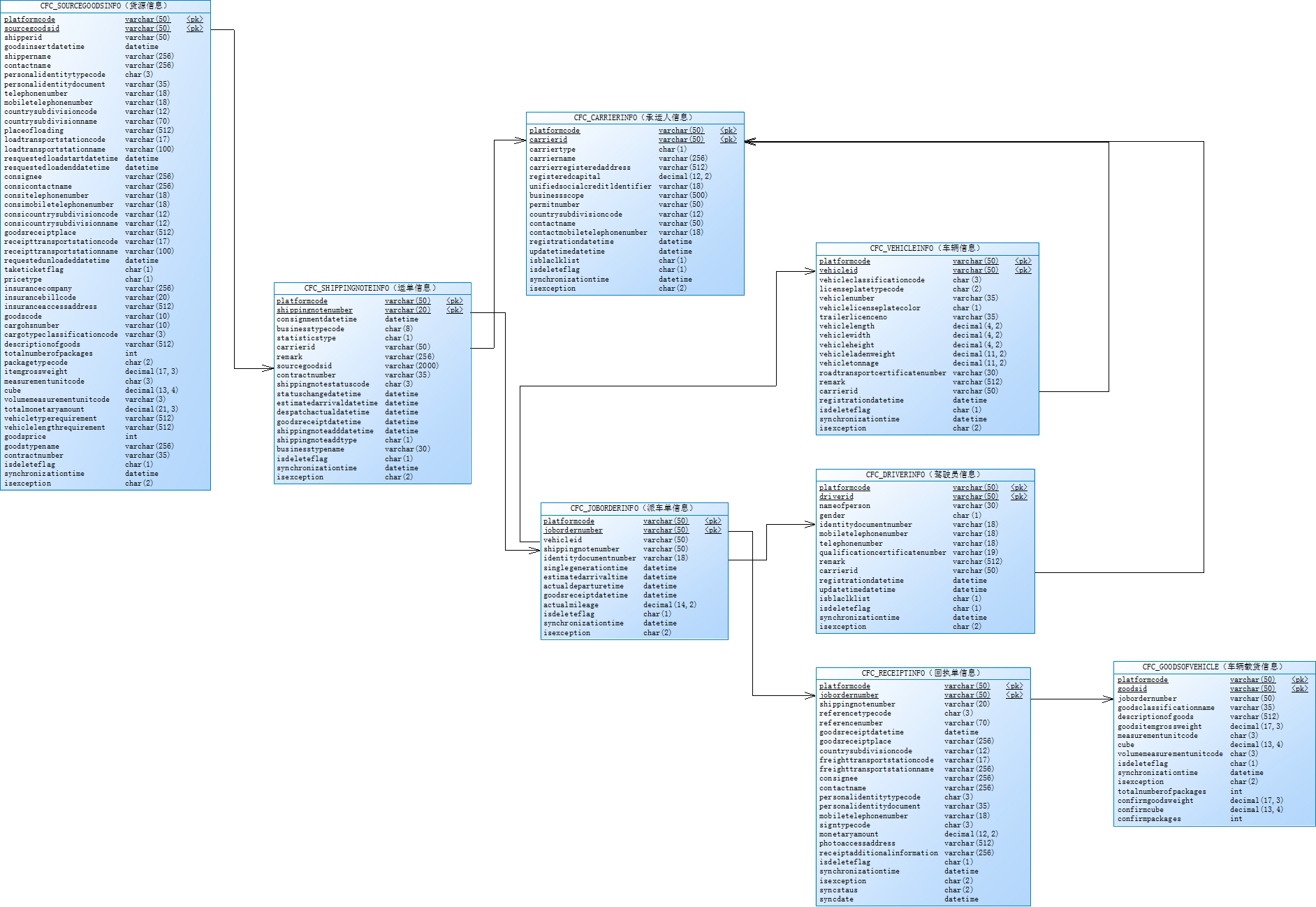
1、阅读《江苏省无车承运人监测与服务平台接入说明(省平台)》 和关系图.png2、准备前置机。(做好前置机安全防护工作开启防火墙,安装杀毒软件,定时备份数据等)前置机要求(1 台或 2 台):数据交换服务器 8 核 CPU, 3...
通过前面的2篇教程Windows服务器端内网穿透工具frps安装及使用教程Windows客户端内网穿透工具frpc安装及使用教程我们已经可以通过阿里云服务器远程到非公网的电脑了,如果自启动的话那就更完美了。1、设置frps自启动...

之前我们讲了frp在windows服务器下的配置,本课程我们讲下客户端frpc的配置,c就是client了。我们之前已经完成了frp的下载,不会下载的看我们之前的文章:Windows服务器端内网穿透工具frps安装及使用教程首先,我们...

首先我们需要下载内网穿透工具frp的,下载地址是:https://github.com/fatedier/frp/releases目前最新的是0.25.3,frp_0.25.3_windows_amd64.zip用于64位的服务器,frp_0.25.3_windows_386.zip用于32位的服务器,当...
TeamViewer现在是越来越严格,本来是想买他的服务的,但是感觉太贵了,每年要1000多。而且最近我的TeamViewer打开一直提示:未就绪,请检查你的连接,我估计是ip是被封了。于是找到了frp,1000多我可以买个阿里云服...

整体的项目结构是这样的,A项目是一个web项目,B项目也是一个web项目,B依赖于A项目,我们在maven编译的时候也报错:xxx程序包不存在但是我们又能进到所谓的不存在的程序包里面。是因为有些IDE没法很智能的做到,直...
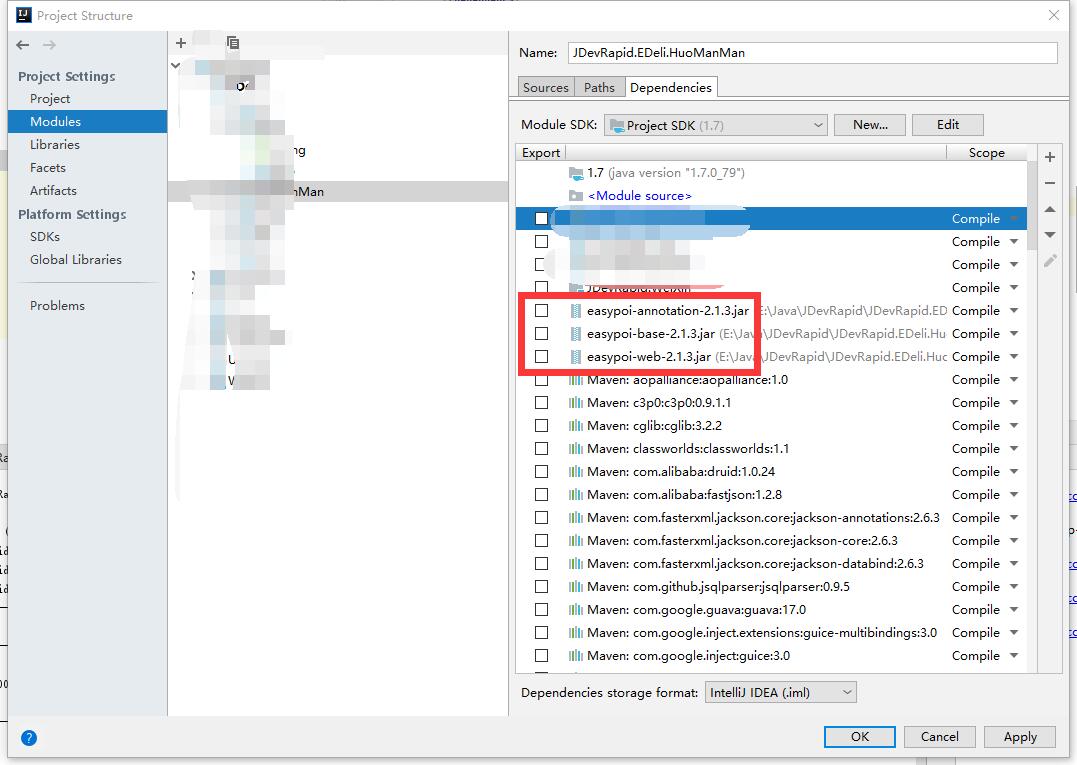
idea开发,maven编译的时候发现报错:程序包不存在如上图所示,easypoi是我在lib目录下自己添加的jar包。但我们在错误代码下又能进到该类的classes文件,就是编译通不过。要解决程序包不存在的问题的话只需要在pom文...
大商创多用户商城2.7.3.3版本版本主要进行了以下的bug修复1、新增一键补单功能,已生成账单的遗漏订单,一键重新生成新的账单2、优化后台审核提现3、优化后台编辑商品重量输入文本框仅支持输入数字4、优化后台删除商...
Hadoop集群搭建安装hadoop下载hadoop将下载的hadoop包解压缩到/usr/local文件夹下配置hadoop环境变量配置hadoopcd hadoop/etc/hadoop/修改core-site.xml<property> <name>fs.default....
CentOS设置163的yum源的过程cd /etc/yum.repos.d/ rm -rf * cp /usr/local/CentOS6-Base-163.repo . # 自己的repo文件移动到/etc/yum.repos.d/目录中:cp /usr/local/Cen...
案例需求数据格式:日期 用户 搜索词 城市 平台 版本需求:筛选出符合查询条件(城市、平台、版本)的数据统计出每天搜索uv排名前3的搜索词按照每天的top3搜索词的uv搜索总次数,倒序排序将数据保存到hive表中实现思...
create table students(name string, age int); load data local inpath '/usr/local/spark-study/resources/students.txt' into table stud...
下载hive解压到/usr/loca/进入conf目录,mv hive-default.xml.template hive-site.xml,修改hive-site.xml<property> <name>javax.jdo.option.ConnectionURL</name> &l...
Hive是目前大数据领域,事实上的SQL标准。其底层默认是基于MapReduce实现的,但是由于MapReduce速度实在比较慢,因此这两年,陆续出来了新的SQL查询引擎。包括Spark SQL,Hive On Tez,Hive On Spark等。Spark SQL与...
工作原理SqlParseAnalyserOptimizerSparkPlan性能优化设置Shuffle过程中的并行度:spark.sql.shuffle.partitions(SQLContext.setConf())在Hive数据仓库建设过程中,合理设置数据类型,比如能设置为INT的,就不要设...
UDF用户自定义函数。Scala版本实例package cn.spark.study.sql import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.SQLContext import&...
Spark 1.5.x版本引入的内置函数在Spark 1.5.x版本,增加了一系列内置函数到DataFrame API中,并且实现了code-generation的优化。与普通的函数不同,DataFrame的函数并不会执行后立即返回一个结果值,而是返回一个Col...
Spark SQL支持使用JDBC从关系型数据库(比如MySQL)中读取数据。读取的数据,依然由DataFrame表示,可以很方便地使用Spark Core提供的各种算子进行处理。这里有一个经验之谈,实际上用Spark SQL处理JDBC中的数据是非...