
transform以及广告计费日志实时黑名单过滤案例实战
transform操作,应用在DStream上时,可以用于执行任意的RDD到RDD的转换操作。它可以用于实现,DStream API中所没有提供的操作。比如说,DStream API中,并没有提供将一个DStream中的每个batch,与一个特定的RDD进行join的操作。但是我们自己就可以使用transform操作来实现该功能。DStream.join(),只能join其他DStream。在DStream每个batch的R...


transform操作,应用在DStream上时,可以用于执行任意的RDD到RDD的转换操作。它可以用于实现,DStream API中所没有提供的操作。比如说,DStream API中,并没有提供将一个DStream中的每个batch,与一个特定的RDD进行join的操作。但是我们自己就可以使用transform操作来实现该功能。DStream.join(),只能join其他DStream。在DStream每个batch的R...
updateStateByKey操作,可以让我们为每个key维护一份state,并持续不断的更新该state。首先,要定义一个state,可以是任意的数据类型;其次,要定义state更新函数——指定一个函数如何使用之前的state和新值来更新state。对于每个batch,Spark都会为每个之前已经存在的key去应用一次state更新函数,无论这个key在batch中是否有新的数据。如果s...
人人商城目前有5个版本,很多人可能都被这5个版本搞乱了吧,下面就由编程入门为大家解释下5个版本的区别,首先从包含的功能上来说他们5个版本分别开店版>分销版>商家版>VIP尊享版>企业开源版。下面,我们来说说5个版本包含的具体功能吧。开店版的功能小程序、商城首页、商品管理、实体商品/虚拟商品/虚拟商品(卡密)/批发商品/记...
TransformationMeaningmap对传入的每个元素,返回一个新的元素flatMap对传入的每个元素,返回一个或多个元素filter对传入的元素返回true或false,返回的false的元素被过滤掉union将两个DStream进行合并count返回元素的个数reduce对所有values进行聚合countByValue对元素按照值进行分组,对每个组进行计数,最后返回<K, V>的格式reduceBy...
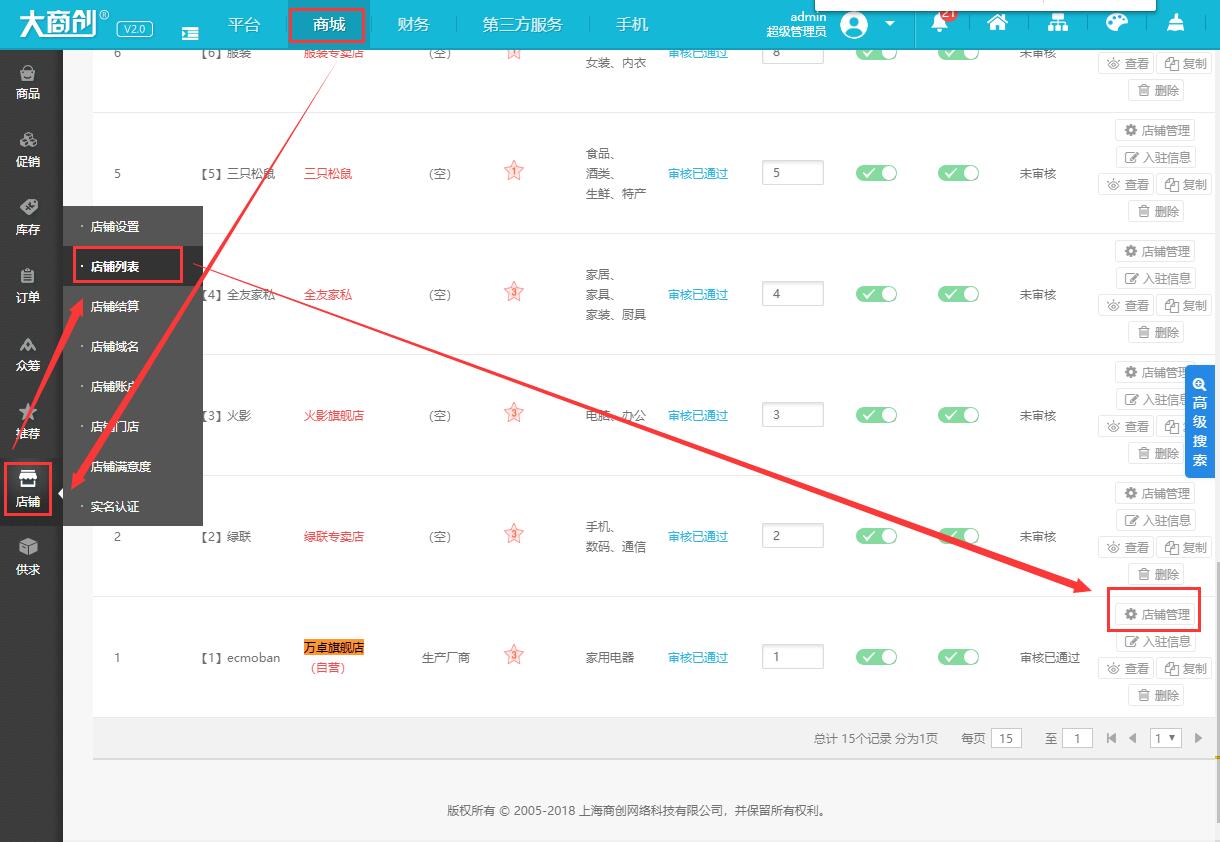
本文介绍如何修改或重置大商创商家的登录密码,实际运营过程中,忘记商家后台的用户名和密码也是非常常见的,具体步骤如下1、首先,登录大商创的后台,依次点击【商城】→【店铺】→【店铺列表】,我们以修改“万卓旗舰店”的店铺用户名为例,我们再单击【店铺管理】2、在大商创的“店铺-分派权限”页面的“店铺权限”页面,可以看到“登录名...

本文介绍如何修改或重置大商创会员的密码,具体步骤如下1、首先我们来到会员的列表页面,依次单击【平台】→【会员】→【会员列表】,比如我们需要修改“ecmoban”这个会员,我们再单击【查看】2、在【编辑会员账号】页面的【基本信息】页面,我们可以看到【新密码】和【确认密码】2个文本框,在这里重置或修改会员密码即可。经过上述的2步操...
基于Direct的方式这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的...
基于Receiver的方式这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Sp...
Socket:之前的wordcount例子,已经演示过了,StreamingContext.socketTextStream()HDFS文件基于HDFS文件的实时计算,其实就是,监控一个HDFS目录,只要其中有新文件出现,就实时处理。相当于处理实时的文件流。streamingContext.fileStream<KeyClass, ValueClass, InputFormatClass>(dataDirectory) streamingContext.fil...
输入DStream代表了来自数据源的输入数据流。在之前的wordcount例子中,lines就是一个输入DStream(JavaReceiverInputDStream),代表了从netcat(nc)服务接收到的数据流。除了文件数据流之外,所有的输入DStream都会绑定一个Receiver对象,该对象是一个关键的组件,用来从数据源接收数据,并将其存储在Spark的内存中,以供后续处理。Spark St...
transform以及广告计费日志实时黑名单过滤案例实战
2019-04-17 12:00:19
updateStateByKey以及基于缓存的实时wordcount程序
2019-04-16 22:00:48
人人商城开店版、分销版、商家版、VIP尊享版、企业开源版5个版本的区别
2019-04-16 22:00:18
DStream的transformation操作概述
2019-04-16 18:00:43
大商创如何重置或修改商家店铺登录密码?
2019-04-16 12:00:41
大商创如何重置或修改会员密码?
2019-04-15 22:00:48
输入DStream之Kafka数据源实战(基于Direct的方式)
2019-04-15 18:00:53
输入DStream之Kafka数据源实战(基于Receiver的方式)
2019-04-15 12:00:37
输入DStream之基础数据源以及基于HDFS的实时wordcount程序
2019-04-14 22:00:32
输入DStream和Receiver详解原理介绍
2019-04-14 18:00:49
