Thrift JDBC、ODBC Server
Spark SQL的Thrift JDBC/ODBC server是基于Hive 0.13的HiveServer2实现的。这个服务启动之后,最主要的功能就是可以让我们通过Java JDBC来以编程的方式调用Spark SQL。此外,在启动该服务之后,可以通过Spark或Hive...
Flume搭建
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可...
Spark源码编译
掌握了源码编译,就具备了对Spark进行二次开发的基本条件了!如果你要修改Spark源码,进行二次开发,那么首先就得从官网下载指定版本的源码,然后倒入你的ide开发环境,进行源码的修改;接着修改完了,你希望能够将...
Spark集群搭建
Spark安装下载Spark-bin-hadoop将下载的Spark-bin-hadoop包解压缩到/usr/local文件夹下修改Spark-bin-hadoop文件夹名字为spark配置环境变量sh vi .bashrc export SPARK_HOME=/usr/local/spark export PATH=$PATH:...
kafka集群搭建
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞...
Zookeeper集群搭建
ZooKeeper集群搭建搭建Zookeeper的目的是为了后面搭建kafka,搭建kafka的目的是后面的spark streaming要进行实时计算,最常用的场景就是让Spark streaming接通kafka来做实时计算的实验。下载安装ZooKeeper下载ZooKee...
易用性:标准化SQL支持以及更合理的API
标准化SQL支持以及更合理的APISpark最引以为豪的几个特点就是简单、直观、表达性好。Spark 2.0为了继续加强这几个特点,做了两件事情:1、提供标准化的SQL支持;2、统一了Dataframe和Dataset两套API。在标准化SQL支...
Hive搭建
仅仅在spark1上搭建下载安装HIVE下载hive,下载bin版本,不要下载src版本将下载的hive包解压缩到/usr/local文件夹下修改夹名字为hive配置环境变量下载安装mysql安装mysql serveryum install -y mysql...
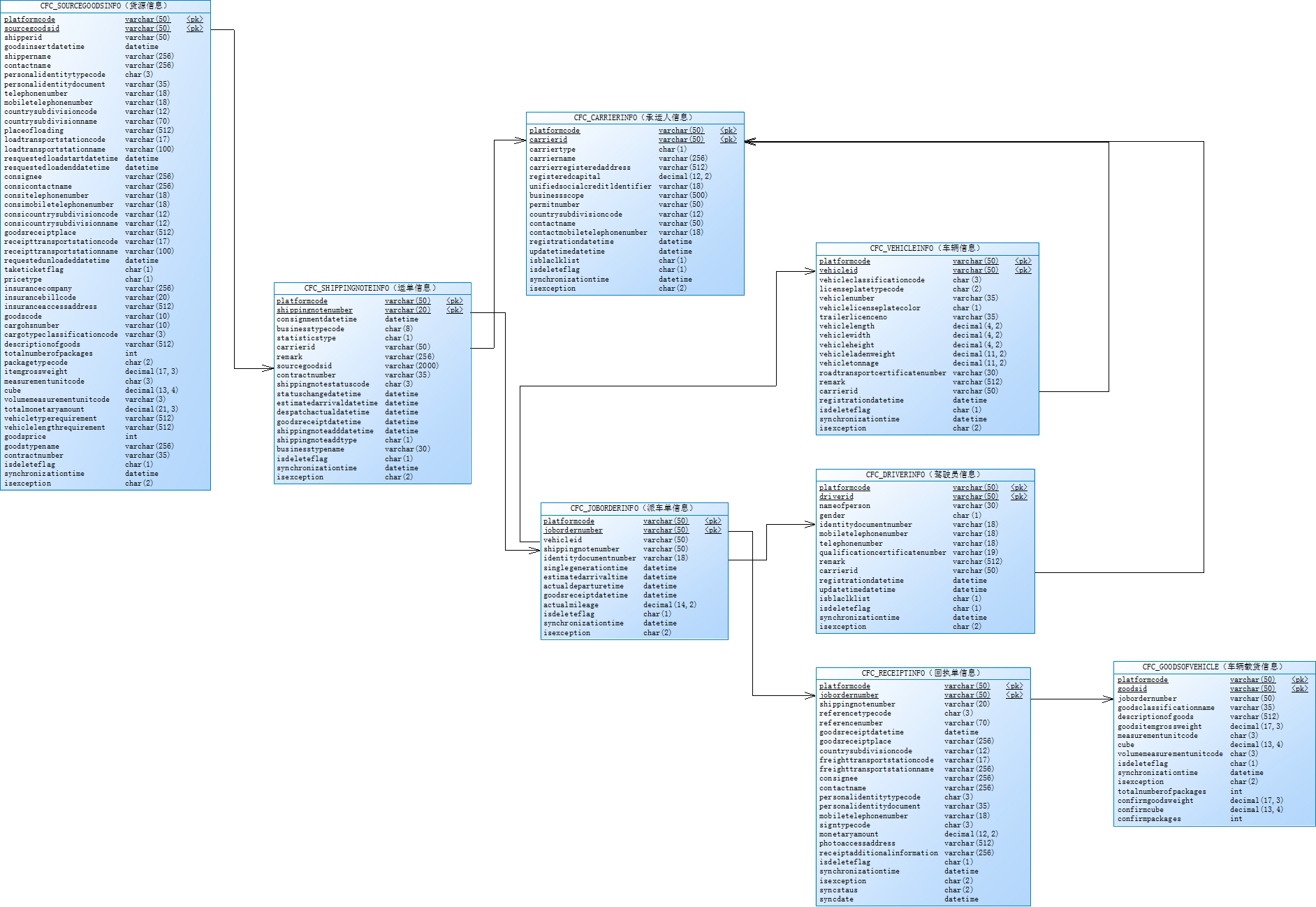
省无车承运人监测与服务平台接入前期准备工作
1、阅读《江苏省无车承运人监测与服务平台接入说明(省平台)》 和关系图.png2、准备前置机。(做好前置机安全防护工作开启防火墙,安装杀毒软件,定时备份数据等)前置机要求(1 台或 2 台):数据交换服务器 8 核 CPU, 3...
Windows客户端内网穿透工具frp设置开机自启动
通过前面的2篇教程Windows服务器端内网穿透工具frps安装及使用教程Windows客户端内网穿透工具frpc安装及使用教程我们已经可以通过阿里云服务器远程到非公网的电脑了,如果自启动的话那就更完美了。1、设置frps自启动...