
SparkStreaming简介
大数据实时计算介绍Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架。它的底层,其实,也是基于我们之前讲解的Spark Core的。基本的计算模型,还是基于内存的大数据实时计算模型。而且,它的底层的组件或者叫做概念,其实还是最核心的RDD。只不多,针对实时计算的特点,在RDD之上,进行了一层封装,叫做DStre...
大数据实时计算介绍Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架。它的底层,其实,也是基于我们之前讲解的Spark Core的。基本的计算模型,还是基于内存的大数据实时计算模型。而且,它的底层的组件或者叫做概念,其实还是最核心的RDD。只不多,针对实时计算的特点,在RDD之上,进行了一层封装,叫做DStre...
新闻网站关键指标离线统计背景新闻网站版块新闻页面新用户注册用户跳出需求分析每天每个页面的PV:PV是Page View,是指一个页面被所有用户访问次数的总和,页面被访问一次就被记录1次PV每天每个页面的UV:UV是User View,是指一个页面被多少个用户访问了,一个用户访问一次是1次UV,一个用户访问多次还是1次UV新用户注册比率:当天注册用户数 ...
Spark SQL CLI是一个很方便的工具,可以用来在本地模式下运行Hive的元数据服务,并且通过命令行执行针对Hive的SQL查询。但是要注意的是,Spark SQL CLI是不能与Thrift JDBC server进行通信的。如果要启动Spark SQL CLI,只要执行Spark的bin目录下的spark-sql命令即可sh ./bin/spark-sql --jars /usr/local/hive/lib/mysql-connector-java-5.1...
Spark SQL的Thrift JDBC/ODBC server是基于Hive 0.13的HiveServer2实现的。这个服务启动之后,最主要的功能就是可以让我们通过Java JDBC来以编程的方式调用Spark SQL。此外,在启动该服务之后,可以通过Spark或Hive 0.13自带的beeline工具来进行测试。要启动JDBC/ODBC server,主要执行Spark的sbin目录下的start-thriftserver.sh命令即可start...
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与...
掌握了源码编译,就具备了对Spark进行二次开发的基本条件了!如果你要修改Spark源码,进行二次开发,那么首先就得从官网下载指定版本的源码,然后倒入你的ide开发环境,进行源码的修改;接着修改完了,你希望能够将修改后的源码部署到集群上面去,那么是不是得对源码进行编译,编译成可以在linux集群上进行部署的格式包吧!编译过程下载spark...
Spark安装下载Spark-bin-hadoop将下载的Spark-bin-hadoop包解压缩到/usr/local文件夹下修改Spark-bin-hadoop文件夹名字为spark配置环境变量sh vi .bashrc export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib source .bashrc配置Spark修改spark-env...
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个...
ZooKeeper集群搭建搭建Zookeeper的目的是为了后面搭建kafka,搭建kafka的目的是后面的spark streaming要进行实时计算,最常用的场景就是让Spark streaming接通kafka来做实时计算的实验。下载安装ZooKeeper下载ZooKeeper将下载的ZooKeeper包解压缩到/usr/local文件夹下修改ZooKeeper文件夹名字为zk配置环境变量配置ZooKeeper配置zoo.cfg`sh cd...
仅仅在spark1上搭建下载安装HIVE下载hive,下载bin版本,不要下载src版本将下载的hive包解压缩到/usr/local文件夹下修改夹名字为hive配置环境变量下载安装mysql安装mysql serveryum install -y mysql-server service mysqld start chkconfig mysqld on安装mysql connectoryum install -y ...
 乐企税务服务平台怎样自动开票?
2024-04-01 12:33:55
乐企税务服务平台怎样自动开票?
2024-04-01 12:33:55
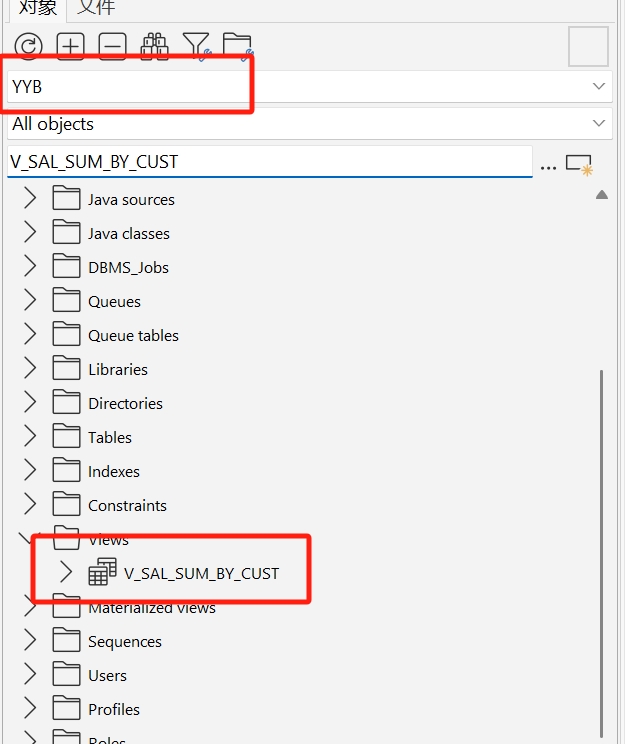 ORA-00942错误表示"表或视图不存在"
2024-03-29 07:31:45
乐企平台是什么?
2024-03-28 12:30:27
乐企中发票额度有效期是多久?
2024-03-27 10:20:11
乐企数电票额度
2024-03-27 10:16:52
乐企自动开票怎么开?
2024-03-26 13:29:01
乐企直连是什么模式?
2024-03-25 12:50:29
什么是JNPF低代码平台?
2024-03-23 13:36:50
乐企直连是什么意思
2024-03-23 13:20:47
税务乐企平台是什么?
2024-03-22 14:08:06
ORA-00942错误表示"表或视图不存在"
2024-03-29 07:31:45
乐企平台是什么?
2024-03-28 12:30:27
乐企中发票额度有效期是多久?
2024-03-27 10:20:11
乐企数电票额度
2024-03-27 10:16:52
乐企自动开票怎么开?
2024-03-26 13:29:01
乐企直连是什么模式?
2024-03-25 12:50:29
什么是JNPF低代码平台?
2024-03-23 13:36:50
乐企直连是什么意思
2024-03-23 13:20:47
税务乐企平台是什么?
2024-03-22 14:08:06
