
Windows客户端内网穿透工具frpc安装及使用教程
之前我们讲了frp在windows服务器下的配置,本课程我们讲下客户端frpc的配置,c就是client了。我们之前已经完成了frp的下载,不会下载的看我们之前的文章:Windows服务器端内网穿透工具frps安装及使用教程首先,我们...

Windows服务器端内网穿透工具frps安装及使用教程
首先我们需要下载内网穿透工具frp的,下载地址是:https://github.com/fatedier/frp/releases目前最新的是0.25.3,frp_0.25.3_windows_amd64.zip用于64位的服务器,frp_0.25.3_windows_386.zip用于32位的服务器,当...

前言
TeamViewer现在是越来越严格,本来是想买他的服务的,但是感觉太贵了,每年要1000多。而且最近我的TeamViewer打开一直提示:未就绪,请检查你的连接,我估计是ip是被封了。于是找到了frp,1000多我可以买个阿里云服...

maven项目找不到war包下的类:程序包不存在
整体的项目结构是这样的,A项目是一个web项目,B项目也是一个web项目,B依赖于A项目,我们在maven编译的时候也报错:xxx程序包不存在但是我们又能进到所谓的不存在的程序包里面。是因为有些IDE没法很智能的做到,直...
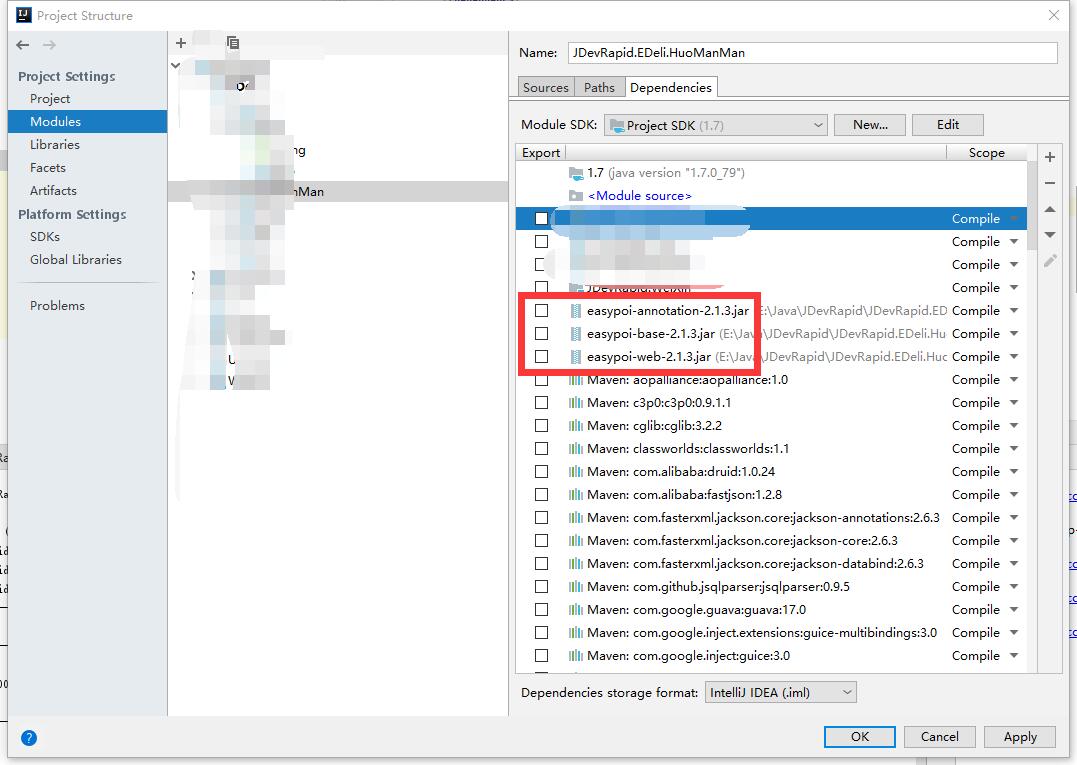
maven无法加载本地手动添加的jar包问题:程序包不存在
idea开发,maven编译的时候发现报错:程序包不存在如上图所示,easypoi是我在lib目录下自己添加的jar包。但我们在错误代码下又能进到该类的classes文件,就是编译通不过。要解决程序包不存在的问题的话只需要在pom文...
大商创多用户商城2.7.3.3版本+微商城+拼团+供应链+砍价+小程序更新内容
大商创多用户商城2.7.3.3版本版本主要进行了以下的bug修复1、新增一键补单功能,已生成账单的遗漏订单,一键重新生成新的账单2、优化后台审核提现3、优化后台编辑商品重量输入文本框仅支持输入数字4、优化后台删除商...
Hadoop集群搭建
Hadoop集群搭建安装hadoop下载hadoop将下载的hadoop包解压缩到/usr/local文件夹下配置hadoop环境变量配置hadoopcd hadoop/etc/hadoop/修改core-site.xml<property> <name>fs.default....
CentOS集群搭建
CentOS设置163的yum源的过程cd /etc/yum.repos.d/ rm -rf * cp /usr/local/CentOS6-Base-163.repo . # 自己的repo文件移动到/etc/yum.repos.d/目录中:cp /usr/local/Cen...
与Spark Core整合之每日top3热点搜索词统计案例实战
案例需求数据格式:日期 用户 搜索词 城市 平台 版本需求:筛选出符合查询条件(城市、平台、版本)的数据统计出每天搜索uv排名前3的搜索词按照每天的top3搜索词的uv搜索总次数,倒序排序将数据保存到hive表中实现思...
Hive On Spark使用
create table students(name string, age int); load data local inpath '/usr/local/spark-study/resources/students.txt' into table stud...




